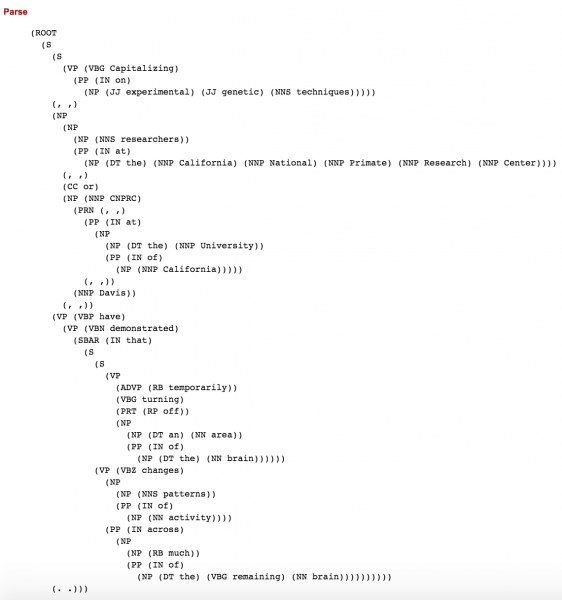
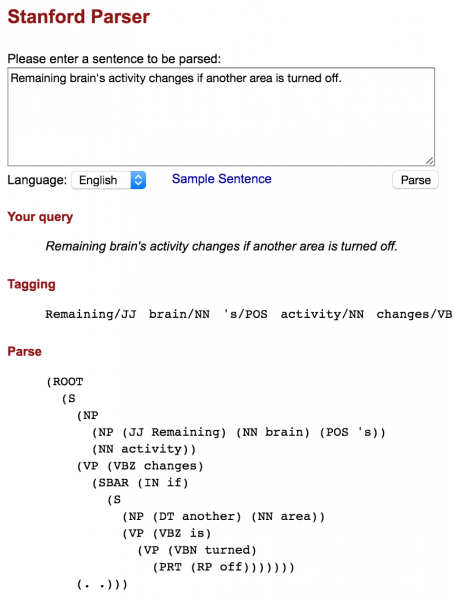
Hi tarnation,
How is it going?
For a few months now, I’ve been strengthening my mnemonic studies and I believe you and I might have similar ideas (actually, this is not the first post from you that resonates with me). My main objective is to remember knowledge, and to me, the main container of knowledge in the World is “books” (at least, that’s the one I enjoy most; of course, Wikipedia is a runner-up too). Therefore, I’ve been dedicating myself to the memorisation of books. Your “sentence structure” idea resonates so much with mine that I decided to give you a (very rough) idea of what I have been musing about.
There is a huge discussion about wether we use language to represent knowledge in our minds, wether we think in words or images, how memories are represented. Instead of diving into it right now, I must just state my standpoint (even if extremely naive and uninformed for now) that I believe the “truth” is always in the middleground. There is no doubt that images aid memory, even if they are their intrinsical composition or not, but we use language all the time, and I believe we must think in terms of it somehow – memories, at some point, must borrow from language structure and, thus, sentence structure. I propose that sentences are the units of memories that we must strive to extract from general knowledge. Yet this will be a lot of work.
My idea is that “reading well” is a precondition to remembering knowledge. Not only we need to really understand what we read, but most importantly, we must know how to separate the “signal from the noise” in order to capture the gist that must be remembered. Therefore, after highlighting, annotating, classifying, etc. a book, we must be able to outline it. By outlining, I use the sense of Mortimer Adler’s book “How to read a book”, and mean creating an hierarchy of the building parts of the book, each having its own unity. Such unity should be as concise and informative as possible, and ideally stated in the form of a sentence – a sentence as simple as possible, “but not simpler”. Such nested sentences would form a network that would represent the book; a network conducive to proper memorisation.
I propose that such partitioning of the book should be done in a bottom-up approach: after reading and highlighting and taking notes, we would split and merge passages and establish the unity of each small group of sentences, proceeding until one sentence characterise the whole book. The granularity of this effort depends on one’s objectives towards the book. So the levels per se would help memorisation: If you just remembered the unity of the entire book, it would be better than nothing; but remembering that unity could assist you in remembering the unities of the main parts of the book, and so forth. Eventually, you might get to the leaves of the network and remember the whole sequence of the main passages that you have selected as noteworthy. If we establish a logical and systematic way of linking the adjoining levels, we might be able to traverse the network beginning from any node. This would be a way of trying to aid our own natural ability of following chains of associations.
Of course, this is not simple and there are thousands of unanswered questions, but now I come to your sentence structure idea (and I, in advance, ask you to forgive my prolixity). Every node would be a sentence and it would be the unity of its children-nodes. Now, imagine the parsed tree of that sentence, like you have already. Like you, I believe that each key word of this tree should become an image. But unlike you (at least, based on what I grasped from your idea), verbs, nouns and adjectives wouldn’t translate directly to verbs, nouns and adjectives in our images. I am far from definite answers, but my idea is that any word should be translated to the most concrete word possible. This is far from trivial. Concreteness is a psycholinguistic attribute of words that have been studied for quite a long time (see e.g., Paivio, 1968 and Brysbaert et al., 2014). But my point here is that, for instance, verbs should not be translated into actions in the image. I believe actions should be let purely for the imagination, in spite of the success of PAO-like systems. Furthermore, actions in imagination may be much more non-sensical than what common verbs imply, so we should profit from this fact instead of restrain it. So, a verb would become a solid, concrete image just like anything else. What then would indicate the part-of-speech of each “concrete image” would be their arrangement in the image. What should that be? I have no idea. This is a project for years. But I have been slowly studying from “Art composition” to the “Visual Language of Comics” to come up with ideas that would define rules for “mental image composition” – a mental grammar – while still allowing freedom enough for our imagination to consolidate memories by being as non-sensical and exaggerated as possible.
Now, we turn to links between levels. How would one node relate to the children-nodes? Where would all these images be placed? In fact, the answer for both questions is only one. The rough and incomplete idea is that from the parsed tree of the sentence, we can establish its “main event” (see UzZaman et al., 2011). Usually, this main event is a verb. Now, here comes the tricky part: this main event would provide a memory palace where the images corresponding to the children-nodes would be placed. I have an idea of how this should be accomplished and I have been making a few tests, but it is too crazy an idea to talk about right now. Anyway, somehow, the object itself should be turned into a memory palace and have its children-images placed along it. Yes, I am talking here about imaginary memory palaces and I am quite sure they will never be as effective as real well-know memory palaces. However, I believe their scalability and the long-term-memory goal of the method justify their use.
If all that could be possible, how would actually remembering such a book take place? Here, we can think in terms of computer science algorithms for traversing networks. Possibly, a gradual spaced-repetition regime of remembering could begin by using a “breadth-first-search” algorithm. We would begin remembering the unity of the entire book. In being successful, we would then “dive into” the main event of the image. This would lead us to our first-level memory palace. There, we would find, say, three images that would correspond to the main three parts of the book (this “part” is based on your understanding, it need not relate to the table of contents of the book). If successful, we would proceed in the same manner until we can recall all the details we have encoded in the leaf-nodes of the network. Once that is accomplished, we can then begin using a “depth-first-search” algorithm. Beginning from the first image of the unity of the entire book, we would keep diving into the main event of the first image of each memory palace until we are in the first leaf-image of the book. From there, we exhaust the memory palace where it is located to remember the first few facts of the book. If we can’t directly link the last image of this memory palace to the first one of the next memory palace in the same level (a link that wasn’t explicitly established before, but that our natural memory might have established on its own), then we “move” to the complex image one level above (corresponding to the main event that formed the memory palace we are at). This image will in turn be located inside a memory palace where the next image will provide the cue for the next (lower-level) events and so on. I know this is a bit hard to visualise, but if you have a computational background (which I believe you have), you might be grasping what I am saying. If there is interest in further discussions, I might try to make some images to help our reasoning.
Now, we can mix both methods whenever we want to remember a specific fact. We may begin, as always, from the root-node, the unity of the entire book, but we could, in theory, begin anywhere we desired. From there, we try to remember which part of the book (child-image) might contain the fact we are looking for while making a breadth-first search. When we find the correct image, we move depth-wise. And proceed in such a way until we find our fact. Of course, hopefully, by then, our natural memory and its huge capacity for non-linear association will suddenly bring the fact to our minds, the network will shade into oblivion and we will keep reasoning about the newfound fact as usual.
Well, this “rough” idea ended up almost like a dissertation, so I apologize for that. I know I went well beyond the “sentence structure” part of the idea, but it would make no sense without context. It is indeed the central part of the whole idea and that’s why I felt urged to tell you about. There is a lot more to it, but as I mentioned, everything is too fuzzy right now to comment too much. I have piles of books and scientific papers to read on cognitive science, computer science, philosophy, psychology, linguistics, etc. before I can speak clearly about such complex – but hugely fascinating – subject, which is the Art of Memory.
All my best,
M.