Eu estava desconfiado de que a separação de fonemas do major system não funcionava para palavras em português, e resolvi tirar dados estatísticos em cima disso.
Fiz uma análise do livro Dom Casmurro, do Machado de Assis, extraindo apenas os substantivos do texto. (Utilizei python e a biblioteca NLTK para fazer isso)
Com o major system original, temos a seguinte distribuição de fonemas:
Major System Original
0 : s, z
1 : t, d, th
2 : n
3 : m
4 : r
5 : L
6 : j, ch, sh
7 : c, k, g, q
8 : v, f, ph
9 : p, b
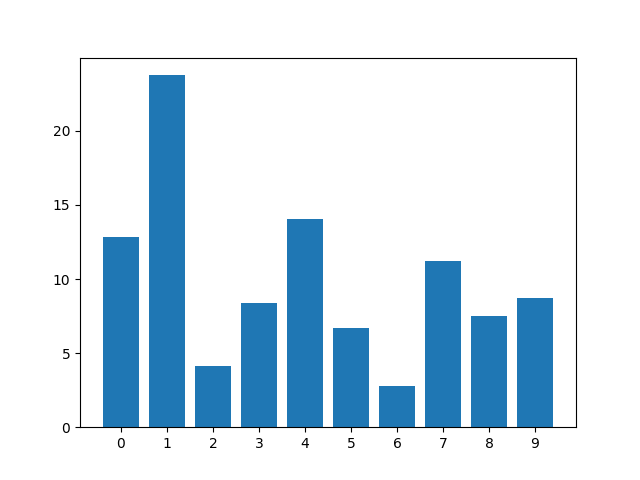
Logo percebi alguns problemas. Os sons de T e D no português são muito mais comuns, e equivalem a mais de 20% dos fonemas encontrados na minha análise.
Já o N e o J são mais difíceis de acontecer, sendo menos de 5% cada um.
Obs: Não considerei sons do tipo “maNga”, “laraNja”, “soMbra” para o N e M pois isso mais atrapalha do que ajuda ao tentar pensar em palavras, já que são o mesmo fonema e não tem como definir se devemos considerar como som de N ou de M.
Minha ideia foi quebrar o T e D em categorias diferentes, enquanto eu junto o N e o M em uma mesma categoria. Também resolvi re-ordenar alguns números por questões de preferência pessoal.
Major System Português
0 : s, ce, ci, ç, z
1 : m
2 : d
3 : t
4 : r
5 : L
6 : p, b
7 : k, q, ca, co, cu, ga, go, gu
8 : v, f
9 : n, x, j, ge, gi
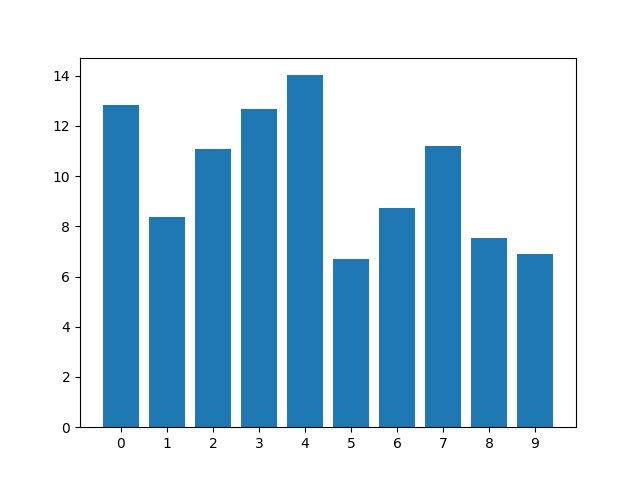
O resultado final ficou muito mais balanceado, onde a menor porcentagem foi o número 5 (L), com 6,68% dos casos.
Num mundo ideal, cada número teria uma distribuição de 10%, e acredito que essa distribuição é a mais próxima disso que podemos chegar em português, mantendo a diferença clara entre os fonemas.
Sei que minha análise tem muito espaço pra erros, e que esses dados não são 100% corretos. Mas a ideia é ter uma noção geral da distribuição. Fiz a análise com outros textos também, e os resultados mantem proporções muito parecidas.
O que acharam da ideia? Alguém já tentou algo parecido?