BTW my wife is going to use this “Turbulent: 95%” against me for the rest of my life!
![]()
BTW my wife is going to use this “Turbulent: 95%” against me for the rest of my life!
![]()
Ha, I figured you for an INTJ or an INTP. ![]()
When I was given my results, the psychometrician told me I was just barely over the J side of the line between INTJ and INTP. The theory stills seems a tad suspect to me, but I have to admit the results seem good. Even though misfits like you and I do not seem not to match the usual mold, the evidence suggests we really are just products of a standard formula.
Getting back to other things: how do I feel inside my letter-based memory palace?
Well, it’s not exactly the same as reality, but there is a definite feeling of dimensionality. My images stretch out dimensionally from left to right. I start outside the iron gate looking straight inside to see the crane and skull-apartment structure in center view. Then I need to perambulate past the alley to get to the library. At that point the skull-structure and iron gate begin to disappear on the left. Next I actually have to go inside the vestibule to see Ms Locklear doing, ummm, something, then come back outside again in order to proceed further to the right toward the naval ship. As the ship and the dock come into view, the library now does an exeunt, stage left.
All this is intended to show that I do indeed experience dimensionality in a way that is similar to reality, even if not precisely the same. Spacing seems like an easy experience to synthesize from the imagination.
As far as the realism, I don’t expect this method will ever feel so realistic as to be confused with a palace taken from reality, but it seems to me it is exercising my hippocampus in a very comparable way. Plus, I think I can improve on my experience with tweaking, practice and the arcane wisdom of alchemy.
Regards,
Darn
Thanks a lot for your report. It is very interesting indeed.
I keep hoping (probably, rather naively) to find a way to simulate the “being there” sensation just with the imagination. The feeling of actually seeing an image located at a specific locus is so real (and useful) that I can’t help trying to do so. There is a ton of literature to peruse in search for any kind of answer, but I don’t think I’ll ever live enough to read all that is necessary.
But, since I am quite stubborn, I have recently bought a very interesting book that I think might bring many insights. I tried to go to the heart of the matter and ended up finding this pearl named “The case for mental imagery”, by Kosslyn et. al. It is a very academic book, but not hard to read – just dense. Unfortunately, I have only skimmed most of it for now. What I want to tell you is just something that your report reminded me of.
I am sure they do and they call it “image scanning, which consists of shifting one’s attention over a visualized object”. Also from the book:
So, they did actual tests with humans and proved it to be so. The book shows all the criticisms that arose from these experiments and tries to refute them all. I haven’t made my mind about the controversy yet, but, of course, I want to believe it and your claims support it. One interesting thing is that it suggests (I believe) that if mental athletes would spread their images across smaller distances, they could speed up their recall times.
I am very interested in these experiments because there might be unexplored ways to heighten the spatial awareness of artificially conjured loci such as the ones in your method. This is a fascinating topic that fits the fourth main problem I am trying to tackle (post #27), which is “how to store the mnemocoded sentences”. However, I think that when time comes for us to really delve into the matter, we should open another thread, lest we digress too much.
Just for completeness sake, I should mention that I’ve also bought another book that I deem essencial for understanding what we are up to when thinking about image representation in our minds. The book is called “Mind and its evolution: a dual coding theoretical approach”, by Allan Paivio. I risk saying that this guy is the scientific father of modern mnemonics. But, of course, I need to read his book first to ascertain that.
Best,
M.
I forgot to ask you something:
In your “cranial nerv” example, you ended up with 11 loci each of which corresponds to one letter. However, the number of loci you want to have should be the number of information pieces you want to store, not the number of letters your keyword/key expression has.
How to cope with that?
This is pretty much the same problem people have with memory palaces – they can’t plan beforehand the amount of loci they will need – so they end up creating portals, elevators, wormholes, whatever. I never liked these solutions though.
How do you do it?
Thanks.
M.
I try to pick my keywords to fit my needs. If I need more letters, I can use more keywords. I think I can find ways to come up with extra keywords, but usually that is just creativity without a plan.
I have also been thinking of reusing the keywords in different ways. In fact I did something like that here. It wasn’t all the letter method at work. I used Crane and Cranium before applying the letter method–combined them, really. Hmmm, technically, I guess they might be a case of the “image becoming the locus”, to borrow from Bateman and r30.
But I also was thinking about using syllables as a basis for generating new loci (in contrast to using individual letters for that same purpose).
Another possibility might be to reuse the letters, but assign them new locus elements. So, first time round, the letter G might be a garage, the second time a garden.
So, I seem to have a few different options to generate at least as many characters as I need. It would be more aesthetically pleasing if I always had the exact amount I need, or if I didn’t have to count. The main thing is to alway to have enough loci.
Stupid thing is, the Cranial Nerv example would have been Cranial Nerve (note the inclusion of the final “e”) had I not placed olfactory with the damned bird. That would have been so much more elegant. Oh well, live and learn.
As far as the feeling of dimensionality and the effort to heighten the spatial awareness of artificially conjured loci goes, another source of inspiration might come from the pseudoscience called neuro-linguistic programming, or NLP. I will probably draw some heat for saying this, but it does seem to me to be pseudoscience. Even ao, it has some gems, in my opinion. I don’t like the golly-gee-whiz I can control your mind type-hype, but there are a number of things that do seem to me to have value. One has to do with ideas about modulating visual images to change one’s feelings and perceptions.
An example they might give would be to imagine (or remember) yourself brushing your teeth last week, then imagine you’re brushing your teeth today (or even next week). Now try to compare the two images. Now ask yourself, "What is different between these two images that allows me to perceive one as representing last eek while the other represents the present, or the furture.
This is a brilliant question, imo, whether or not you buy their exact answer. Both images should be pretty much the same. Chances are you brush your teeth in very similar ways each day and usually in the very same location. What is weird is that the images represent different times, and somehow you can tell the difference in your mind’s eye, even when the two images are almost identical. Even if the two images are almost identical, they still must differ in some key aspect. But what could it bee.
Just for the practice, I memorized the quoted sentence by building the loci on the fly,using techniques we previously discussed, creating rooms for subject, verb, then additional rooms for subsequent clauses. It went fairly smoothly, allowing me to capture the sentence in one read plus a single review. It wasn’t spectacularly fast, but in line with learning a new skill, like memorizing a deck of cards–it should be possible to memorize faster with practice. The overall set of images seems to be pretty unique, so may be reasonably scalable. It also occurred to me to see if I could recite the sentence backward. That also seemed pretty easy, though admittedly not especially useful, as far as I can see.
Next will need to start practicing and refining my techniques, but using multiple sentences. I will focus on picking a few key sentences from texts that interest me–not so much consecutive sentences as sentences that capture the essential points that interest me. This should give me a better sense of scalability.
Darn
Hi tarnation,
I have been absent from this thread “textually”, but not at all mentally. I have made great progress and I owe most of it to you and your ideas. I’ll try to explain what I’ve been up to as efficiently and concisely as possible (although I doubt I’ll be successful).
I had posed a sequence of four questions that must be answered in order to come up with my “dream mnemonic system” in post #27, but now, I will simplify them slightly, so that I can actually devise a working system to be applied really soon. In fact, time is urging me to finally get more practical than theoretical. I don’t think I have told you, but I have just begun Law School (for inexplicable reasons, in a point of life that 99% of reasonably coherent people would never think of such nonsense), so I have a daunting memorization task ahead of me. But that’s actually one of my greatest motivations for putting up with Law School: to turn me into my own guinea pig for mnemonic investigations!
That said, these are my simplified set of questions and the corresponding answers. I’ll then develop each of the answers.
1 - How to extract the gist of texts?
“Reading well”, i.e., understanding, selecting quotations, re-organizing and grouping them into new summarizing sentences.
2 - How to encode the resultant quotations and/or sentences?
Creating semantic scenes.
3 - How to mentally store them?
Connecting scenes through their keywords, using syllabic pegs, and forming a story hierarchy.
All this, of course, sounds simpler than it is. However, while I still don’t know if it will work, I finally have a system that I can actually develop by using it. I have also started creating Python programs to assist me in using it, but that’s for later.
1 - How to extract the gist of texts?
First, as I have said elsewhere (probably many times), I believe the key for memorizing any text is to create an hierarchical structure based on sentences, where each level summarizes the level below. Each sentence in a given level is the parent-node of a set of related sentences in the level below – the child-nodes. I have come up with a full (albeit preliminary) modus operandi for the process of reading, selecting and summarizing a text, which I’ll describe here very briefly.
I am using the software Atlas.ti for this, a CAGDAS, or Computer-assisted qualitative data analysis software. Ever since I bumped into QDA, I realized its principles should be used for reading well. While I haven’t gotten deep into QDA yet, its most basic principle – coding – underpins my approach for reading well and generating the “hierarchy of summarizing quotations and sentences”, herein simply called story hierarchy.
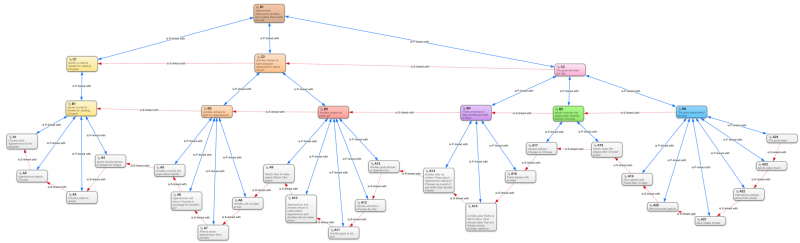
As an example, I took Josh’s attempt of summarizing Iliad, which unfortunately accomplished only Book 1. The image below shows the 19 bullet-points he created. I won’t enter the matter of how to reach such a summary (which is reading well), so let’s just assume we want to memorize these bullet-points; not verbatim, but as well as possible. By using Atlas.ti, I select as quotations (I am sticking with the term used by the software) the sentences or clauses I believe convey one single idea, capable of being represented my one image, being it a complex one or not. I must say here that, in spite of our thread’s title, sentence structure is exactly the one aspect I won’t talk about. Whatever quotation you decide to represent in a single image will form what I like to call a semantic scene. I’ll talk more about this in a minute.
After all quotations are created (with whatever granularity you desire, which could even be verbatim), they are coded as level “A” and numbered consecutively (this could be, of course, any naming scheme). Note that I have further divided Josh’s 19 points into 24. We now proceed from the “bottom up”, grouping quotes by the common conveyed idea and coding them accordingly. Be aware that these quotes may be disjoint, so different parts of the text may be set to a single code, adding flexibility to the method. This next level would be level “B” and to each group of quotes should be created a new summarizing quote. Here, we’ll be naturally self-correcting us, because whenever we can’t express the whole idea of the group of quotes as one single quote or sentence, that indicates we should split the group again. Eventually, as the image shows, we’ll have all quotes grouped in as many levels we deem necessary.
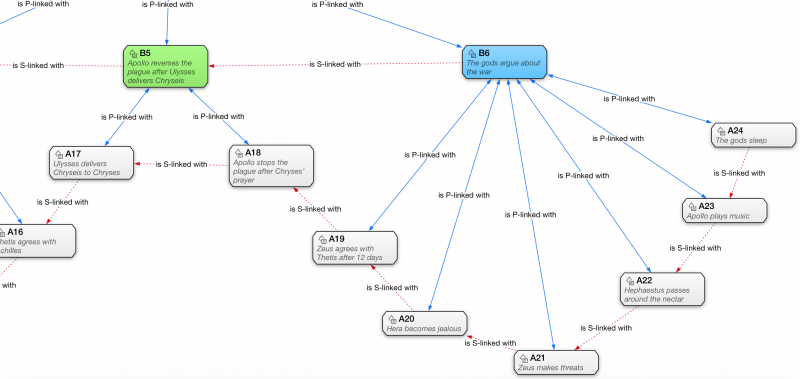
Now, the software provides a very nice capability. You can set relations among codes, which can have different semantics. Here, at least for now, I am not as much interested in the semantics of the relation as I am in simply connecting the codes into the story hierarchy. Nevertheless, I have set two types of relations – P-links and S-links – which I shall explain in a minute. That done, the software allow us to visualize the structure as a graph, as the next two images show.
Now, that structure is what we are going to memorize.
2 - How to encode the resultant quotations and/or sentences?
Each node of the hierarchy now becomes a semantic scene. Ideally, sentence structure will be maintained through a complex image where each element refers to a word and/or part-of-speech, like we’ve been talking about. For now, however, I won’t dive into this issue. The only thing that matters is that we create an image for representing the quotation and that it be semantically encoded (your minimal encoding). That I believe is important. However, I became very fond of your method of combining semantics and sound resemblance as much as possible and I have been trying to do so as well. I should emphasize though, that he main focus of this post is on how to combine the different levels of information, not how to encode each node, and that again is based on your ideas, as number 3 below explains.
3 - How to mentally store them?
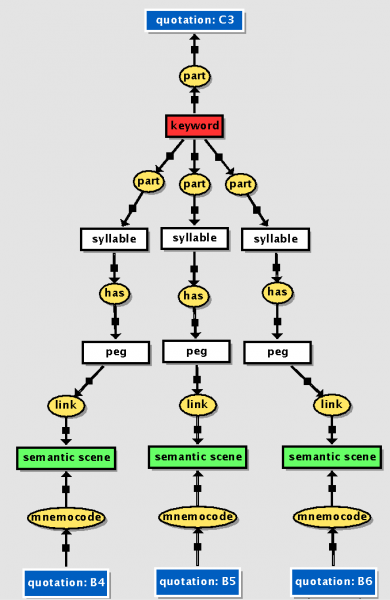
Each parent-node will be linked to its child-nodes through syllabic pegs. By analyzing the story hierarchy, we know beforehand how many children each node has, so we can select the number of keywords accordingly. So, we proceed iteratively by first selecting the “main event” of the parent-node; if it has a number of syllables equal or greater than the number of children, that’s enough; otherwise, we select another keyword. All this could in theory be done automatically using some kind of program, but I am far from this level of sophistication and what I mean here is based on manual case-by-case decisions. Each syllabic peg with then be mnemonically linked to the semantic scene from the lower level. Of course, a “peg dictionary” must be maintained. Below, is a “conceptual graph” representation of this linking between levels.
I really liked your idea of using letters for selecting pegs to add further information and it perfectly resonated with my idea of hierarchical structures for remembering. Then, you hinted on the idea of using syllables and, after experimentation, I thought it to be much better. Letters are not good-enough cues for remembering the associated peg, whereas entire syllables are much better. In fact, this method you created is fantastic for any routine mnemonic task such as remembering a shopping list: just visualize one word or short expression that summarizes your task ahead (maybe that one item your wife will kill you if you forget) and proceed to attach the other items to the corresponding syllabic pegs. Simple and brilliant!
I must also stress that the system I propose does NOT use loci at all. It is purely a link-peg system and, while I consider it greatly inferior to a loci-based system, it is much more practical and ideal for a first approach to the problem. With time and practice, I hope to naturally turn it into a loci-based system such as your letter-based one, that converts words into imaginary memory palaces. As I develop the semantic scenes, they can naturally (and gradually) become detailed enough so as to provide adequate loci for placing the pegs. That has always been similar to my main objective (see the “3D peg” idea), but I realized now that I was demanding too much of my meager imaginary capacities. I can’t do that for now, but I can use pegs and links. By embedding your “syllabic pegs” idea with the hierarchical structure I propose, I have finally a full-fledged (although preliminary) prototype-system, which I can test.
Before talking about the computer-based implementation I am working on, I should just clarify the link structure of the second-to-last image. Blue “P-links” are “peg links”, the ones that connect the syllabic pegs of the parent-node with the semantic image of the child-node. Note that they are symmetric links (each has two arrows), meaning that they are simple mnemonic links with no need for any structure: in principle, pegs will be easily distinguished from semantic scenes. Red “S-links”, in contrary, are “story links”, or the usual pair-wise linking strategy, and they are not essential to the method proposed. They are something that could be used to further enhance the method and to provide a faster way to recall the images and, thus, the text. But I should develop this idea as I practice with the system, not now.
Sorry for the huge post and thanks for reading this. Most importantly, thanks for providing the inspiration.
Best,
M.
(to be continued)
Hi Mnemoriam,
Glad to hear from you.
I am very gratified to know that you have made such progress, and flattered to think that my ideas helped.
If I am going to take credit for anything, this @&#%€!£# conscience of mine (soon to be surgically removed, if it doesn’t stop flaring up) requires that I mention that some key aspects of my ideas were inspired by (or perhaps flagrantly stolen from) others. The Lanier Verbatim Memory System (https://artofmemory.com/video/the-lanier-verbatim-memory-system-part-one-intro-part-two-how-it-works-3433.html), stands out. [Aside: I referred to, but misspelled, Mr. Lanier’s name in an earlier comment (#14), perhaps having misbefuddled his name with a chemical element that I associate with the Incredible Hulk. My apologies, Mr. Lanier.] Mr. Lanier’s goals are a bit different from mine, as this entire post while attest, but some of his methods helped me to figure out how to easily solve certain problems that I had been grappling with.
For people who are primarily concerned with verbatim memorization, and who don’t care for the crazy abstractions and constraints that you and I are so obsessed with, Mr. Lanier’s system may be exactly what the doctor ordered.
For my part, I am continuing to play with memorizing sentences along the lines mentioned in comment #46 and earlier. I want to be sure I can handle multiple sentences without too much difficulty and to achieve worthwhile speeds both encoding and decoding. So far, I am happy with the results, but I need to keep making improvements and adjustments to the system and to generally keep developing my skill.
There are a couple of related tasks that are taking up my time (well, several, actually, but two worth mentioning): the first is to finish memorizing my mnemonic dictionaries for common words and common syllables; the second is to finish memorizing my scrapyard of loci parts. The latter is the sorcerer’s number one source of half-baked materials to be used for building loci-on-the-fly.
I am glad you wrote, “to be continued” at the bottom of your last comment. I do hope you will keep the conversation going, either on this thread, or via pm. You have mentioned so many cool things that I want to keep learning about. Since I am a programmer myself, at least a mediocre one, I would love to see your programs once they are ready for viewing, to see what I might learn from them.
Plus, I am getting mighty curious about the man behind the mask. I have been trying to put together who you are, within the bounds of respect for your anonymity. (I personally don’t like to share my real name or details, except in private email.) I know that you are an INTP and I strongly suspect that you are from somwhere in the British Commonwealth. Most recently, I noticed you used the indefinite article “an” before the letter “h” (as in “…an hierarchical structure”), which seems distinctly un-North American. (I am a Canadian, btw, so guilty of being both North American and a British Commonwealther, though I hope to fool people by favoring the miscreant orthographic habits of the US.) And, while I can only assume you are a male, I am 99% certain you are neither a sheep nor a duck, since you have started Law School at a time of life when 99% of reasonably coherent people–a figure clearly that encompasses all sheep and almost all ducks–would not even entertain such a thought.
So, a non-sheep, non-duck, male INTP from the British Comonwealth, enrolled in Law School at a rather late age, with an obsession for programming a linguistic based mnemonics tool. There can’t be more than one or two million people on the entire planet that fit that profile. I guess I will just have to keep looking for the clues to help whittle it down from there.
Hope to hear from you again soon,
Darn
Hi tarnation,
So, this quote is from your post #46: you are talking about using your sentence-structure-based approach, right? Not your "scrapyard-of-loci-parts-based approach, right? (We are definitely in need for specific nomenclature for all this crazy stuff that we invent/adapt/steal from others/etc.).
I am eager to know how it is working so far, at least once you have a statistically valid sample of results and, of course, if you could share. I am specially curious about how you are managing (in the case of multiple sentences) to generate unique-enough rooms. Also, are you connecting the “mini-memory palaces” of consecutive sentences together or are you leaving them stand alone? While I ask this, I think about how to best search for the stored mnemonic images, both in your approaches and mine. Talking about your sentence-structure-based approach, specially if different sentences are connected, I believe it will be like searching in a memory palace – you will have to walk around the whole place in sequence until you bump with the image you want. What I hope to accomplish with my hierarchical peg-based system is a more efficient recall, but I am not certain it will work out as expected.
For now, it is too early to tell, but the theory is that the combination of “syllabic peg + semantic scene” will provide a greatly memorable peg with very fast recall. If I am faced with a subject I want to recall, I hope to know (through natural memory) what keyword should lead me to the image. Since the image is semantically related to the keyword, it should be reasonably easy. If it doesn’t come to my mind, I might remember the broader subject it pertains to and find it’s keyword. Then, by searching the syllabic pegs of that keyword, I might finally remember which peg is associated to the semantic scene of the subject I want. I hope I am making sense.
I believe that, for reasonably small subjects, say, an article you want to remember, your loci-based method will be faster. You will run through your memory place quickly, visiting your images, which will provide almost direct access to the sentences you want to remember (since their structure will be preserved). But, as the subjects get big, say, a whole 700-page book on a detailed subject, I believe a peg-based system might be faster. Pegs might not come instantaneously to mind, specially because some words might be used many times, thus creating confusion, but I hope that the ability to find solace in the hierarchical structure might compensate for that. I am quite certain, though, that some combination of all these elements (pegs, hierarchies, semantic images, on-the-fly loci, sentence structure) must provide “the” mnemonic system, but (if it even exists) it is no doubt still out there, lost among a dense forest of conjectures, and far from being found.
May I ask how many words, syllables and loci parts your dictionary is already amassing? It is great to know that you are undertaking such a huge task – it is a true incentive.
On my part, I am working on the program and, as soon as I have a better-looking one, I will post about it and, of course, share the code if you want it. I am using a graph structure to store all the information. Each node has a label, a semantic scene, a quotation and a list of keywords separated by their constituent syllables, all of which must be added manually; as well as edges defining how the nodes are connected to each other. Then, the program traverses the graph, building the mnemonic links between nodes. For each node, it reads the list of syllables and try to find a corresponding peg-image in a file containing a “peg dictionary” (which is depressingly empty, for now); if it doesn’t find one, it asks for user input. Then it adds a link attribute to each outgoing edge of that node, which, in essence, is simply a tuple containing the current peg-image and the semantic image of the connected child-node. Sounds complicated, but it is actually really simple (otherwise, I wouldn’t be able to program it). I can then save the entire graph in a file and Python reads it in perfectly whenever I want. I am currently thinking of how to best display the information and how to review it.
I got married in Ireland, but that’s as close as I get to being a British Commonwealther, I am afraid. I also asked my wife (who is not Irish) about sheep and ducks. She said it is more like pigs and parrots. I have no idea where she took that from…
![]()
Best,
M.
Hi Mnemoriam,
What? You are not from the commonwealth!
How did I get that wrong? Your English is impeccable, but I thought I could rule out the United States. Plus, I just read that there are 53 countries in the British Commonwealth. It also encompasses almost 1/4 of the Earth’s surface, which seemed to make it a very good guess.
Still, smarter folks might say that a 25% chance of being right is a 75% chance of being wrong.
So for my next conjecture, I am going to say you most likely come from a continent that begins with the letter A.
![]()
I am on my lunch hour right now, so I will reply to your other comments a bit later when I have time.
Take care,
Darn
Hi Mnemoriam,
Sorry, that was a bit longer than expected–due to a combination of late hours at the office and passing out too early on the sofa.
Right now it seems to me that real success with my sentence structure approach will depend somewhat on the scrapyard approach. At least if I want to memorize larger amounts of materials.
I have been casting about for a book to use as material. Only yesterday, I decided on a small, old paperback that I have wanted to review for many years. It’s called “The New Mathematics”, by Irving Adler. It’s a simple enough read, but when I read it so many years ago, it filled my head with insights and great ideas. The problem is that I forgot the specific details that set my brain on fire.
My plan is to use it to memorize just the parts that interest me–not to try to memorize the whole book verbatim, or anything like that. This is probably representative of how I would like to memorize material. I expect to establish a hierarchy from book title to chapter titles (details to be worked out as I go), then each chapter title will (somehow) link to some number of key sentences from within the chapter. The sentences will be loci-on-the-fly based on each sentence’s structure.
In order to manage a significant number of sentences using a loci-on-the-fly approach, I will need the ability to improvise unique and interesting locations quickly, or at least efficiently. Ultimately, this is a brain plasticity goal. That’s where the scrapyard comes in. Essentially, it is just a big list of elements that can be used to construct loci. The way I imagine it, I will create a journey filled with many things that I can use to build loci, for example lists of furniture, lists of passages, etc. I will wander through these journeys looking for inspiration as I practice improvising new locations and making them very unique. I don’t think I can easily explain the whole plan, but if successful, I should end up developing a powerful set of imagination skills for location building.
Naturally, the scrapyard plan will take time. I will not use that as a reason to delay moving forward with my objectives of reviewing “The New Mathematics”.
One thing I have noticed so far is that some written material lends itself more readily to the structured sentence approach. Up till now, I mostly memorized from Science Daily articles. There I found whole sentences that I wanted to memorize largely as-is.
So far, looking at the Adler book–though I have barely started–it seems I have to pull pieces of information out that interests me and construct an entirely new sentence for memorization. I think that is because I already understand most of the things being spoken about, so most things are not worth mentioning. That leaves bits and pieces–the gems that matter after the dirt and dross has been washed away. So, I am pulling out fragments of sentences and having to reconstruct the, into new sentences that will carry the meaning into the future.
It’s late, will need to leave this coffee shop before I am forcibly removed.
Take care,
Darn
Hi,
That’s a good way of thinking. I am usually guilty of the opposite though – aiming for the great instead of the good and ending up doing nothing. I shall do like you and attack my hierarchical-syllabic-peg idea even though I am far from having the syllabic and number pegs I need. Since this is not a “speed memorisation” endeavour, I see no harm in building the dictionaries on the fly as needed.
The “New Mathematics” book seems to be really interesting. I am waiting for the first used books I ever bought from Amazon to arrive. If they come in good conditions, I’ll order the book. However, I think it’s going to be quite complicated to memorise so many mathematical concepts; I am eager to know how you will do it.
I have recently searched for a simple book as well, but not really to test my new ideas. I want to see if I can apply mnemonic techniques (just plain images and loci) to help my mother remember a little of what she reads. In fact, she has stopped reading altogether and I greatly suspect it is because she simply can’t remember what she read the day before. I chose “A Little History of the World”, by E.H. Gombrich, which is a fascinating, though simple read. I have just started reading it with her and progress is slow – but there is progress.
Keep up the good work with the scrapyard approach and I will share any progress on my part when it happens.
Best,
M.
This is a very interesting conversation. I have been working on something related to this, but without much success.